Input
DINOv2
V-JEPA
VideoMAE
FeatUp
FlowFeat


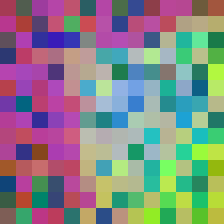
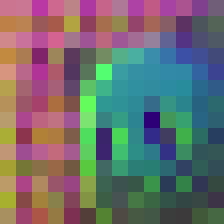
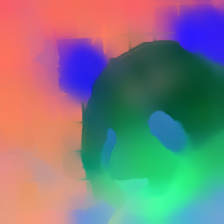




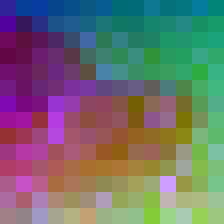




















@inproceedings{Araslanov:2025:FlowFeat,
author = {Araslanov, Nikita and Sonnweber, Anna and Cremers, Daniel},
title = {{FlowFeat}: Pixel-Dense Embedding of Motion Profiles},
booktitle = {NeurIPS},
year = {2025},
}